Ai-Da: Họa sĩ AI đầu tiên có hình dạng giống con người
Trí tuệ nhân tạo AI (Artificial Intelligence) đang có những bước phát triển rất mạnh mẽ, lấn sâu vào cả những lĩnh vực như sáng tạo nghệ thuật, trong đó có hội họa. Dự án robots họa sĩ Ai-Da được phát triển bởi các nhà khoa học tại Đại học Oxford, đã cho thấy những tác phẩm hội họa đầy mới mẻ, đáng ngạc nhiên
- Genetica: Ứng dụng trí tuệ nhân tạo (AI) trong phát triển công nghệ giải mã gene
- AI đầu tiên trên thế giới nộp đơn đăng ký sở hữu trí tuệ tại châu Âu
- Cách thức hoạt động của trí tuệ nhân tạo

Họa sĩ máy Ai-Da Robot
Ai-Da Robot đã trở thành một “Họa sĩ máy” có triển lãm cá nhân (solo) đầu tiên trên thế giới, gây tiếng vang không kém gì những họa sĩ đương đại nổi tiếng. Xưởng vẽ của “Cô” là một căn phòng ốp gỗ nằm trong khuôn viên trường Đại học Oxford, có không gian chẳng khác gì so với xưởng vẽ của họa sĩ chuyên nghiệp với các tác phẩm nghệ thuật bày kín xung quanh.
Ai-Da không chỉ vẽ giỏi, “Cô” còn có thể giao lưu, trả lời các câu hỏi, chia sẻ ý kiến của riêng mình về nhiều vấn đề liên quan. “Cô” có cách phát biểu chậm rãi, dừng lại giữa các câu dường như để tìm từ phù hợp, giống hệt như phong cách của các họa sĩ.
Robot Ai-Da được xây dựng dưới mô hình người thật, từ phần cổ trở lên được đắp da silicon và mang bộ tóc giả tùy chọn. Thân và tay chân của Ai-Da vẫn để ở dạng máy móc cơ khí, nhưng có thể dễ dàng giấu dưới các lớp trang phục.
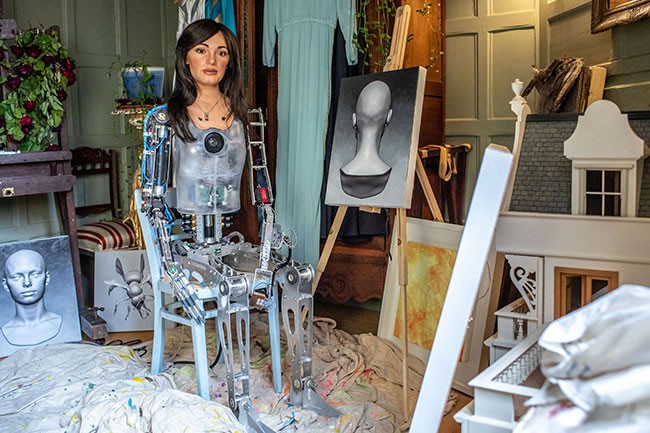
Ngoài khả năng vẽ và pha màu thuần thục, các cử chỉ của Ai-Da cũng khá mượt mà, tuy nhiên gương mặt chưa thực có hồn, đôi mắt thủy tinh gần như bất động, chỉ thỉnh thoảng chớp chớp mi mắt. Điều này làm giảm đi phần nào mức độ biểu cảm, nhưng nếu chỉ nhìn vào tác phẩm của Ai-Da chắc chắn ai trong chúng ta cũng phải giật mình.
Dự án robots họa sĩ Ai-Da được lãnh đạo bởi Aidan Meller cùng nhóm kỹ sư chuyên về robot có các tính năng giống con người do các nhà khoa học tại Đại học Oxford phát triển. Ai-Da phát ra tiếng nói thông qua loa gắn trên ngực, nhưng để quan sát thế giới xung quanh, cô dùng camera gắn trong đôi mắt y như người thật. Các thuật toán giúp Ai-Da ghi nhận hình ảnh và thể hiện lại dưới dạng các bức vẽ được tạo ra bởi các sinh viên đến từ đại học Leeds.
Ai-Da được trang bị công nghệ nhận dạng khuôn mặt, hỗ trợ bởi trí thông minh nhân tạo. Cô có thể ghi lại một hình ảnh trước mặt, đưa hình ảnh này vào kho lưu trữ và xử lý rồi dùng thuật toán để ra lệnh cho chuyển động của cánh tay, để tạo ra các bản phác thảo.

Tất nhiên, trong giai đoạn hiện tại Ai-Da chưa thể hoàn thiện các bức vẽ mà cô ấy chỉ đưa ra “ý tưởng” và phác thảo, sau đó các nhà nghiên cứu phải diễn giải bản vẽ ý tưởng của cô lên mặt phẳng Descartes (dạng đồ thị) rồi chạy chúng thông qua mạng nơ-ron AI, một hệ thống máy tính được mô hình hóa dựa trên não người.
Mạng nơron này sẽ “đọc” các thông số (tọa độ) và tạo ra hiệu ứng lăng kính riêng của mình. Hình ảnh tổng hợp sau đó được in lên canvas và một nghệ sĩ người thật sẽ giúp hoàn thiện bức vẽ.
Giám đốc dự án Meller cho biết: “Chúng tôi coi chương trình này là sự khởi đầu, không còn nghi ngờ gì nữa, AI sẽ trở thành lĩnh vực quan trọng của những năm 2020”. Theo như định nghĩa triết học, sự sáng tạo là một thứ gì đó mới mẻ, đáng ngạc nhiên và có giá trị, nhóm phát triển tin rằng sản phẩm của Ai-Da đáp ứng các tiêu chí này mà mang tới sự phấn kích đáng ngạc nhiên.
Tiềm năng của Ai-Da còn rất lớn và khó có thể dự đoán tài năng của “Cô” sẽ được bộc lộ đến mức nào, nhưng có thể khẳng định rằng nó sẽ không có giới hạn theo thời gian.
Tổ hợp Obvious
Trên thực tế, Ai-Da là họa sĩ AI đầu tiên có hình dạng giống con người và vẽ bằng tay, còn danh hiệu hoạ sĩ AI thành danh đầu tiên phải thuộc về của nhóm Obvious. Vào năm 2015, ba sáng lập viên quốc tịch Pháp gồm Gauthier Vernier, Pierre Fautrel và Hugo Caselles-Dupré đã sử dụng thuật toán dành cho AI có tên gọi là GAN (Generative Adversarial Networks) được sáng tạo bởi Ian Goodfellow nhằm giúp máy tính tổng hợp, phân tích dữ liệu và đưa ra quyết định - ở đây là vẽ tranh.

Có thể diễn giải một cách nôm na là nhóm tác giả dùng 2 nguồn dữ liệu một thật (training set) một ảo (random) để thực hiện đào tạo. Các dữ liệu từ trainning set bao gồm một số hình vẽ, màu sắc cơ bản sẽ được nạp vào máy, kèm theo một số định hướng ví dụ sắp xếp thế nào là hình tròn, hình vuông… Dần dà, máy tính sẽ tạo được tư duy logic cơ bản. Sau đó các tập hợp dữ liệu bất kỳ sẽ được nạp vào tiếp và máy tính “tin rằng” đó chính là các dữ liệu từ ảnh thực.
Cùng với thời gian, máy tính sẽ dần học cách xử lý các hình ảnh phức tạp hơn, ví dụ một bức chân dung gồm các yếu tố cơ bản như khuôn mặt phải có hai mắt, tóc phải mọc trên đầu… nâng cao hơn nữa có thể phân tích đến trang phục, phụ kiện ứng với chủ đề, phong cách hoặc thời kỳ sáng tác.

CAN (Creative Adversarial Networks) là một biến thể phát triển từ GAN được thiết kế để tạo ra tác phẩm nghệ thuật sáng tạo. Nhóm tác giả đã nạp dữ liệu từ khoảng 15.000 bức chân dung khác nhau được vẽ vào khoảng thế kỷ XIV đến XX. Các bức họa này gồm có rất nhiều đối tượng, chất liệu cũng như phong cách hội họa qua nhiều thời kỳ. Sau khi máy tính đã đủ tinh thông, có thể tạm coi là trình độ đọc bức tranh ngang ngửa với chuyên gia, người ta sẽ nạp vào một tạp hợp dữ liệu bất kỳ (tương tự như đưa cho họa sĩ một đống bột màu) và nêu chủ đề bức tranh, họa sĩ máy tính dựa vào đó sẽ phải sáng tác ra một bức tranh tương ứng.
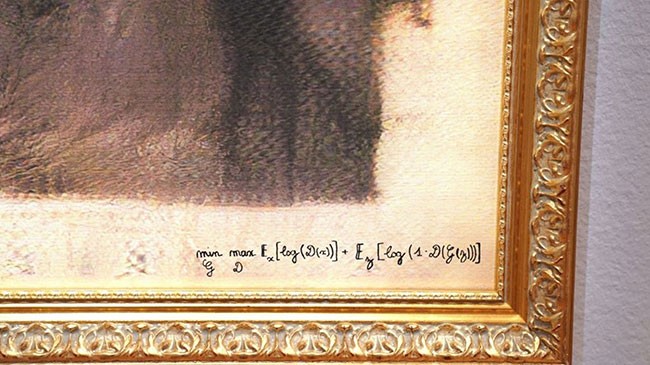
Năm 2018, nhóm tác giả đã công bố bộ sưu tập mang tên Gia đình Belamy bao gồm 11 bức chân dung do máy tính vẽ hoàn toàn. Ở mỗi bức chân dung, phần “lạc khoản” chính là thuật toán cơ bản của GAN min G max D Ex [log (D (x))] + Ez [log (1-D (G (z)))]. Bộ sưu tập đã được bán đấu giá thông qua nhà Christie ở New York và thu được thàn công vang dội.
Midjourney, DALL-E và hơn thế nữa

Midjourney là một hệ thống AI có thể tạo hình ảnh từ các khẩu lệnh, tức là bạn chỉ cần ra đề bài bằng giọng nói, ví dụ chủ đề bức tranh là gì, phong cách hội họa nào, màu sắc ra sao… máy tính sẽ tự động “suy nghĩ” và vẽ ra bức ranh theo tưởng tượng riêng của chính nó. Midjourney đang trong giai đoạn thử nghiệm Close Beta, bắt đầu vào khoảng cuối tháng 2 đầu đầu tháng 3 năm 2022 và hiện đang gây sốt trong giới hâm mộ.

Midjourney là một dự án mở, khuyến khích người dùng tham gia, tất nhiên kèm theo nhiều điều kiện phải đáp ứng. Trong giai đoạn thử nghiệm Beta, chương trình Midjourney chạy chương trình trên một máy chủ Discord riêng, dành cho những người được mời tham gia, và AI được truy cập độc quyền trong máy chủ Discord này.
Midjourney Discord cho phép người tham gia chương trình tạo 25 hình ảnh miễn phí trước khi cần đăng ký sản phẩm, trên các kênh công khai có nhãn “Thành viên mới”. Các nghệ sĩ và nhà thiết kế tham gia thử nghiệm Beta đã bắt đầu chia sẻ những hình ảnh mà họ đã thực hiện bằng cách sử dụng Midjourney lên các nền tảng như Twitter và Instagram.
Ban đầu, các “tác phẩm” được coi là khá ngô nghê nhưng dần dà, chất lượng của chúng đã được nâng cao, đem lại hứng thú cho cả các tác giả lẫn người xem. Tuy nhiên xin nhấn mạnh rằng, Midjourney là một dự án đang trong giai đoạn thử nghiệm beta và nó cũng không phải là một hệ thống máy tính AI hoàn chỉnh.
Vừa qua, một số kênh thông tin có đưa các bức tranh hoàng tráng và “vu” cho đây là tác phẩm được vẽ hoàn toàn bởi trí tuệ nhân tạo bằng Midjourney AI. Nói một cách nôm na, đây là thông tin “fake”. Để cho ra một tác phẩm tương đối hoàn chỉnh cả về chủ đề lẫn cách thể hiện, người dùng phải liên tục tương tác với AI và cung cấp các lệnh để máy có thề dần điều chỉnh theo hướng người dùng mong đợi. Tất nhiên với những nét vẽ và màu sắc, hình khối ít nhiều sẽ mang tính bất ngờ và cho ra kết quả thú vị.

Tương tự như Midjourney, DALL-E cũng là một mạng nơ-ron trí tuệ nhân tạo tiên tiến, có khả năng tạo ra hình ảnh từ lời nhắc văn bản. Dự án do nhóm OpenAI khởi xướng với các xuất phát điểm thú vị. Cái tên DALL-E được ghép từ hai tên: một là Salvador Dalí, họa sĩ trường phái ấn tượng tài ba của xứ sở bò tót; và hai là sản phẩm (tưởng tượng) của hãng phim hoạt hình Pixar - chú (cô) người máy WALL-E nổi tiếng trong bộ phim cùng tên.
Nhóm sáng tạo cho biết cái tên này phản ánh hình ảnh giả tưởng (có thể nói là ít nhiều mang tính hài hước) trong các bức tranh siêu thực của Dalí, kết hợp giấc mơ và tưởng tượng đến từ Hollywood. Được biết, Dalí và Walt Disney đã từng có hợp tác vào năm 1946 trong một phim hoạt hình ngắn mang tên “Destino”. Lạ ở chỗ phải hơn 50 năm sau bộ phim mới được phát hành, có thể qua đây phần nào ta thấy chất vị lai của danh họa.

Mạng nơ-ron thần kinh AI của DALL-E xử lý hàng tỷ ngôn ngữ tự nhiên cũng như học hỏi từ đa dạng các nguồn trên internet. Đây có thể coi là khả năng tự học (tự đào tạo) và về nhiều mặt nó vượt trội hơn một người thông thường. Dần dà, nó có thể tạo ra các câu chuyện, tạo mã lệnh, dịch chéo giữa các ngôn ngữ và thực hiện các phép tính toán học phức tạp khác, bao gồm cả xử lý và sáng tạo hình ảnh.
DALL-E không phải là dự án đơn thuần mang tính chất chơi mà thực tế nó có thể đem lại lợi ích hết sức cụ thể. Ví dụ từ một lệnh văn bản "Một ma-nơ-canh nữ mặc áo khoác da đen và váy xếp ly vàng" nó sẽ đưa ra hàng loạt đáp án bằng hình ảnh hết sức khác nhau và hết sức sáng tạo. Chắc chắn, nó sẽ tìm được ứng dụng đầu tiên ở ngành thiết kế, thử nghiệm trang phục và sau đó là các ngành như thiết kế sân vườn, trang trí nội thất và hơn thế nữa.

Trong hình minh họa là liên tưởng của DALL-E về một quả bơ (Avocado) và chiếc ghế bành. Ai dám nói đây chỉ là những nét vẽ siêu tưởng mà không phải là những gợi ý hết sức thú vị cho các nhà thiết kế nội thất? Rõ ràng, các “Hoạ sĩ AI” đang chứng minh tính đắc dụng của mình và chắc chắn sẽ tìm được “chỗ đứng” xứng đáng trong xã hội tương lai.
Theo Tạp chí Điện tử


























Tối thiểu 10 chữ Tiếng việt có dấu Không chứa liên kết
Gửi bình luận